| 知乎 HADOOP Yarn Federation 跨云多机房调度实践 | 您所在的位置:网站首页 › hadoop 性能 › 知乎 HADOOP Yarn Federation 跨云多机房调度实践 |
知乎 HADOOP Yarn Federation 跨云多机房调度实践
|
1 介绍 HADOOP YARN 在大数据领域中,是整个离线任务调度的核心。它提供了队列、标签等多样化的管理手段,但是在迁移、多机房甚至面对更大的集群时还是有些不足,包括但不限于:集群规模增加后 ResourceManager 元数据的负载,跨云多机房的统一配置等等。知乎 HADOOP YARN 在跨云多机房海量任务调度和迁移领域做了深耕探索,并且已经投入到生产环境应用,已经稳定运行约半年有余。现今对 此进行讲解说明。 2 问题随着知乎业务离线计算规模的不断增加,HADOOP YARN 集群规模必然也不断扩展。由此产生以下 4 个问题: 单集群主节点容量负载问题。单个 YARN 集群管理上千台计算节点的成本越来越高,其中包括:随着集群规模增加对 ResourceManager 的负载,调度资源出现无法充分利用等等。跨云多机房部署。因为庞大的集群规模,很难找到同一地域容纳如此规模集群的机器,由此涉及到跨地域多机房的情况,同时也伴随着迁移机房的可能性。此时就涉及到跨云多机房部署。对于多机房 YARN 集群的部署和管理,现有的选择是:使用同一套 YARN 集群,通过标签形式管理;多机房多套 YARN 集群管理,配置简单,维护成本高; YARN Federation 集群管理,但是官方不建议跨云多机房。跨云迁移问题。如何对 YARN 任务进行迁移从而保证带宽的问题,如何迁移对业务的影响最小,迁移过程如何保证任务的按时产出。调度平台配合问题。不同的部署方式,均需上层调度的配合,包括:知乎自研 http://Data.in 调度平台,业务的物理机器,Azkaban 调度等等。如何让上层调度的改动最小,如何实现高效、稳定的调度方式等等3 调研对于面对的问题,知乎对跨云多机房 YARN 集群架构部署进行相应的调研工作。 其中,直接否定了单集群打标签的方式,因为随着集群扩展,ResourceManager 负载越来越高的问题无法根本解决,而且对于多 label 标签的管理维护成本太高。 对于多机房多集群和 YARN Federation 管理多集群,首先需要对齐一下术语含义。多机房多集群的含义是:多个机房,每个机房独立部署 YARN 集群,YARN 集群之间没有联系。而 YARN Federation 管理多集群,是每个机房部署 YARN 集群,由 YARN Federation 中的 YARN Rourter 进行管理。对于 YARN Federation, 后续会做简单介绍。此时先对比下多机房多集群管理方式和 YARN Federation 管理多集群方式的利弊。 方案优点缺点YARN Federation- 社区推动方案,和社区保持一致,同时也是未来多机房的方向- 配合 HIVE / SPARK 只需对接 YARN Router 模块- 对业务改动最小,只需修改一个配置文件即可- 集群配置信息保持一致,运维成本低- 未来可以通过增加/减少 SubCluster,实现动态扩缩集群- 现有社区对于 YARN Federation 资料和投产实例比较少,可能需要修改源码以支持知乎环境YARN 多机房多集群- 方案成熟,操作简单- 工具现成,不需要投入太多开发的工作- YARN多机房多集群容易导致不同集群的参数配置不一致,维护成本高- 需要为不同集群配置对应的 HIVE/SPARK 客户端- 需要通过不同的参数配置,将作业提交到对应集群,业务端改造成本高- 迁移回滚切换成本较高对比上述方案发现,YARN 多机房多集群方案开发简单,投入工作少。但是缺点也很明显:需要客户端修改配置,利用不同配置,将作业提交到对应集群。未来 YARN 集群规模的增减,客户端也必须进行相应改造。同时,每套 YARN 环境都得搭建对应的 HIVE/SPARK 服务,增加机器成本。还有,YARN 多机房多集群互相没有联系,容易产生配置不一致的情况,维护成本较高。 而使用 YARN Federation,只需业务改造一次,对于跨云多机房使用一套配置,实现后续某个机房集群的上下线对业务无感知。也是因为对外只需提供一套配置,所以对应的 HIVE/SPARK 服务只需提供一套即可,降低机器成本和维护成本。构建 YARN Federation 是将复杂度降低到 HADOOP YARN 层面,提高了业务端开发效率,降低了平台方的维护集群配置成本。还有未来的降本增效,通过 YARN Federation 实现增减集群,更容易达到降本增效的目的。 最终,不管是秉着一劳永逸的想法,还是后续的工作需求,知乎采用了 YARN Federation 架构进行跨云多机房管理和部署,并基于此完成了机房迁移的工作。本专栏会通过知乎海量任务迁移,介绍离线 YARN Federation 的架构部署,以及架构升级中间遇到的问题和处理方式。 先对 YARN Federation 进行说明: 类似于 HDFS Federation , 为了解决ResourceManager的扩展性问题的,避免随着集群的增加,导致 ResourceManager 的负载压力以及调度性能的影响,使用 YARN Federation 统一管理集群,对外提供同一套接口。详细官方链接:https://hadoop.apache.org/docs/stable/hadoop-YARN/hadoop-YARN-site/Federation.html 3.1 YARN Federation 术语说明YARN Router:Router 模块通过访问 State-Store 的配置策略 ,确定将作业分发到特定集群中运行; YARN AMResourceManagerProxy:每个 NodeManager 上均启动一个 AMRMRroxy 服务,作为AM与ResourceManager之间通信的代理;会将AM请求转发到正确的HomeSubCluster。 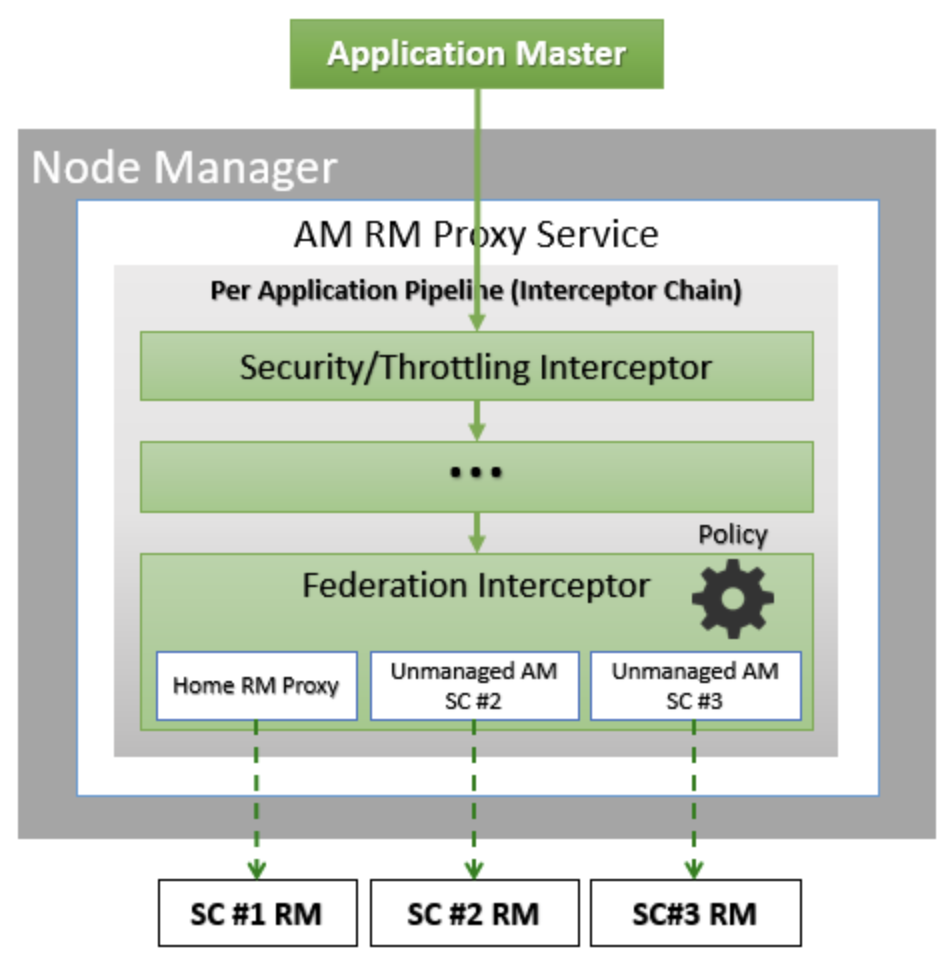 Federation State-Store: 保证状态的持久化,其中包括: policies: 队列的策略信息,确定任务如何在子集群 (SubCluster) 中运行。memberships:子集群 (SubCluster) 信息,通过在子集群中配置(YARN.federation.state-store.heartbeat-interval-secs), 从而向 YARN Router 汇报。applications: 具体作业的 application 信息。3.2 YARN Federation 运行任务流程 YARN Federation 任务运行流程 YARN Federation 任务运行流程Client 端向 YARN Router 提交作业,Router 访问 State-Store,获取作业的运行策略。根据策略确定哪个 ResourceManager 作为 HomeCluster。 AppMaster 通过 AMRMProxy 向 ResourceManager 申请资源。 AppMaster 申请到资源后,通过 AMRMProxy 实现跨集群启动 task 任务,实现任务的运行。 3.3 YARN Federation 策略模块Router Policy:决定哪个子集群为 HomeCluster。AMRMProxy Policy:决定向哪个子集群调度资源。3.4 YARN Federation 策略模式优先级调度:预先分配每个 YARN 集群优先级,当优先级高的集群资源不足之时,再对低优先级集群进行调度;权重比例调度:若是两个子集群的权重为:7:3,70%的任务可能调度到子集群A,30%的任务可能调度到子集群B;负载调度:根据子集群的剩余内存可用量进行调度。4 测试上线4.1 知乎 YARN Federation 策略因为知乎的两个机房跨专线带宽有限,需要禁止使用 AMRMProxy 跨机房调度任务的功能,因此使用了权重比例(1:0)的策略方式。不同机房的 YARN 环境调度是通过队列进行区分,而 YARN Federation 不支持队列与机房绑定(同一队列的任务只能跑在特定机房)。 但是 YARN Federation 队列的调度策略,均是通过访问 ZooKeeper (知乎使用 ZooKeeper 作为持久化存储) 上的 “/federation/policies/队列” 进行策略的访问。所以知乎实现独立路由策略控制服务 ,直接向 ZooKeeper 注册队列的策略服务。主要的架构图如下: 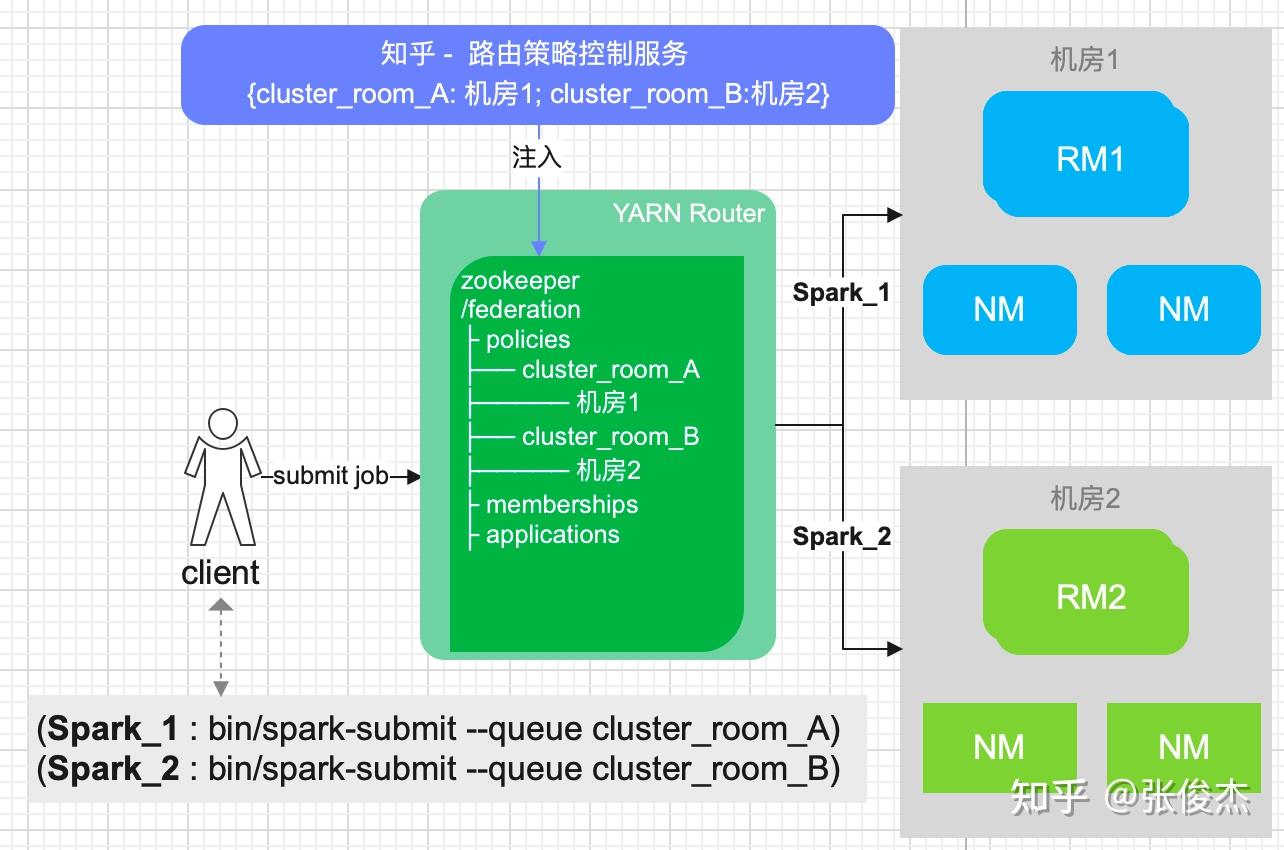 知乎路由策略图 知乎路由策略图比如: 有两个任务 Spark_1 和 Spark_2,分别通过队列 cluster_room_A与队列cluster_room_B提交。在路由策略控制服务中配置这两个队列与机房的对应关系:{cluster_room_A: 机房1; cluster_room_B:机房2}, 将规则直接存储到 ZooKeeper 中的。Client 端提交作业,通过 ZooKeeper 中的路由规则,将 Spark_1 任务路由到机房1,Spark_2 任务路由到机房2。 4.2 作业运行时长对比上线 YARN Federation,必须保证任务依旧可以按时产出。所以需要验证 YARN Federation 架构和原有单集群运行作业时长的对比数据。 4.2.1 测试集群信息集群配置YARN RouterCPU: 4核, 内存: 8G,SSD云盘:40G × 2YARN RM (主备)CPU: 16核, 内存: 64G,SSD云盘:500G × 2YARN NM (8台)CPU: 8核, 内存: 16G,,HDD盘:4096G × 84.2.2 测试模型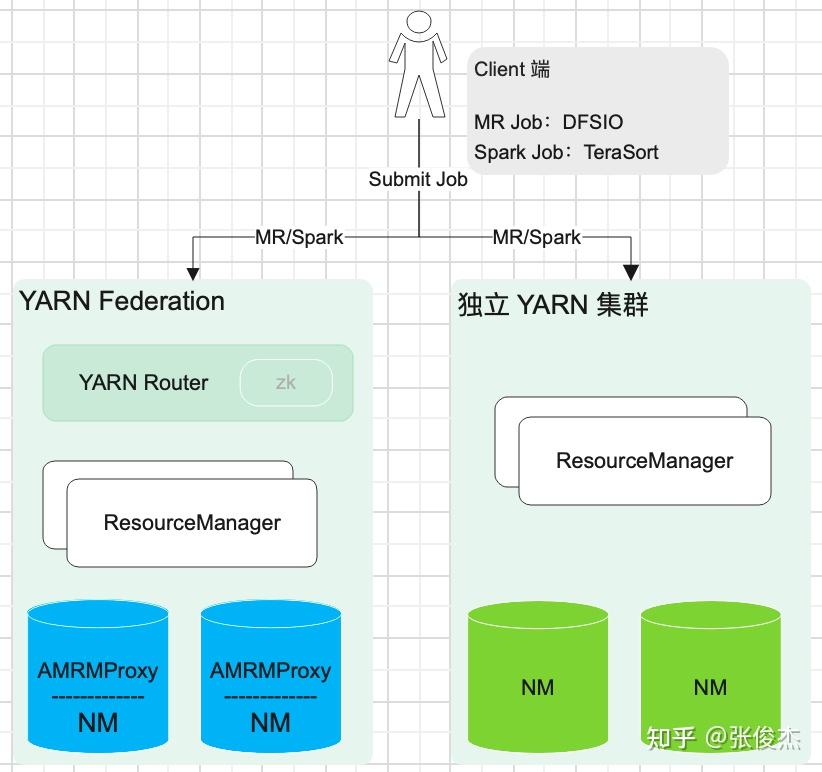 YARN 架构测试模型 YARN 架构测试模型4.2.3 测试结果 模块YARN Federation 集群(分钟)YARN 独立集群(分钟)备注MR19.2319.01多次平均值SPARK29.328.56多次平均值注:因为 HIVE 是由多个 MR 组成,所以测试完 MR 之后,无需进行 HIVE 的测试验证。 4.2.4 总结测试结果符合预期,上线 YARN Federation ,对集群作业运行时长几乎无损耗。同时在 YARN Federation 架构下,也验证 ResourceManager/NodeManager 重启对任务几乎无影响。 4.3 灰度上线功能在实现 YARN 集群架构升级过程中,需要保证现有任务的按时产出,所以必须满足在一段时间内, YARN Federation 集群架构和独立 YARN 集群架构并存,均可以进行作业的提交。比如:ResourceMaanger 先上线一台备节点,再完成主节点的上线;NodeManager 先上线 10 台机器,再上线 100 台机器等等。知乎的 HADOOP 版本是 3.2.1,不支持该功能,所以需要进行 patch 修复:YARN-10229。 4.4 支持 YARN global policy generator (YARN GPG) 功能因为 YARN Federation 官方架构没有对过期的 application 信息进行清理,所以 ZooKeeper 中 /federation/applications 信息只会越来越多,最终导致 ZooKeeper 的崩溃。所以 YARN JIRA 中增加 GPG 模块:YARN GPG 服务框架 , YARN application 清理。 但是在上线运行过程中,发现存在 application 误删的可能,调查原因发现代码模块: // hadoop-YARN-project/hadoop-YARN/hadoop-YARN-server/hadoop-YARN-server-globalpolicygenerator/src/main/java/org/apache/hadoop/YARN/server/globalpolicygenerator/applicationcleaner/ApplicationCleaner.java Set RouterApps = getAppsFromRouter(); // hadoop-YARN-project/hadoop-YARN/hadoop-YARN-server/hadoop-YARN-server-globalpolicygenerator/src/main/java/org/apache/hadoop/YARN/server/globalpolicygenerator/applicationcleaner/ApplicationCleaner.java public Set getAppsFromRouter() throws YARNRuntimeException { String webAppAddress = WebAppUtils.getRouterWebAppURLWithScheme(conf); LOG.info(String.format("Contacting Router at: %s", webAppAddress)); AppsInfo appsInfo = (AppsInfo) GPGUtils.invokeRMWebService(conf, webAppAddress, "apps", AppsInfo.class, DeSelectFields.DeSelectType.RESOURCE_REQUESTS.toString()); Set appSet = new HashSet(); for (AppInfo appInfo : appsInfo.getApps()) { appSet.add(ApplicationId.fromString(appInfo.getAppId())); } return appSet; }getAppsFromRouter() 获取集群所有的 application 信息,因为跨云多机房导致的 application 量过大,无法按时返回结果,所以只能返回某些 appliation 信息。没有返回 application 信息的 id,就存在误删的可能,导致 SPARK/MR 作业运行失败。下图为 SPARK 任务运行失败的堆栈信息。 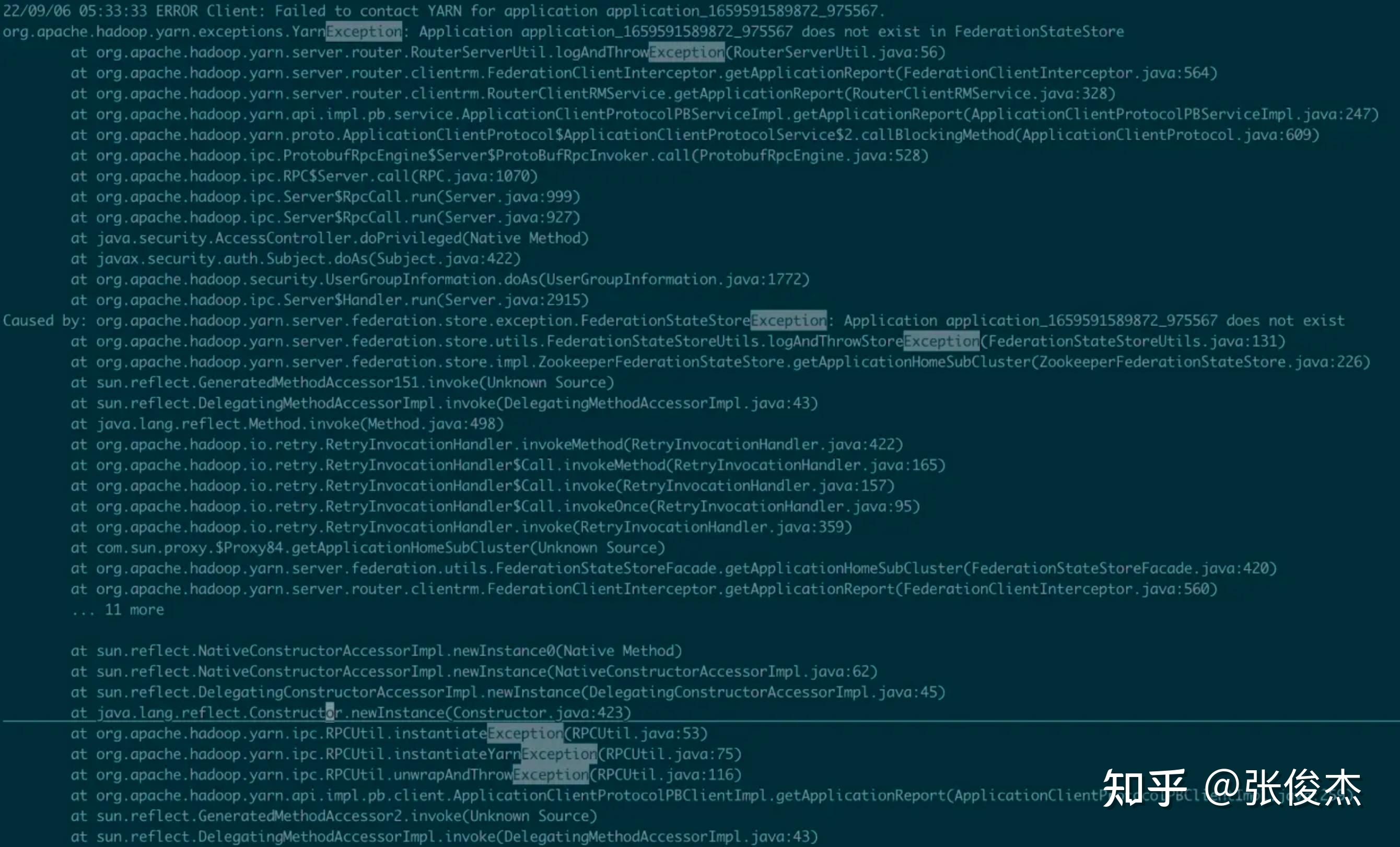 Spark 任务失败堆栈 Spark 任务失败堆栈知乎的解决方案是:将 YARN Router 拉取 application 方式改成每个 SubCluster 方式拉取本集群的 application 进行对比删除。具体流程是: 每次 application 任务提交到 YARN 集群,均会带有 HomeSubCluster 信息。获取到 HomeCluster,通过:subClusters.get(app.getHomeSubCluster()).getRMWebServiceAddress(), 得到对应的 WebServices;每个 application 连接 WebServices 服务,到对应的集群中确定是否存在该 application 信息,若是存在,则返回true,若是不存在,再进行删除操作。后续会对 YARN Router 中的 ZooKeeper 信息进行监控打点的功能实现,现今的监控是通过 HADOOP 集群之外的方式实现,不符合 HADOOP 自管理规范。现今该功能已经上线,在现有规模集群下,每 30 分钟轮训一次,删除一次需 10+ 分钟,对 ZooKeeper的压力比较小。已稳定运行 3 月有余。代码开源地址:YARN-11387。 4.5 YARN Federation子模块的独立 ZooKeeper 建设YARN Federation 中的组件,包括:YARN Router、每个独立的 YARN子集群,知乎实现了每个组件均使用独立 ZooKeeper,保证互相之间不影响,尽可能将风险控制在最小。 如下图所示: 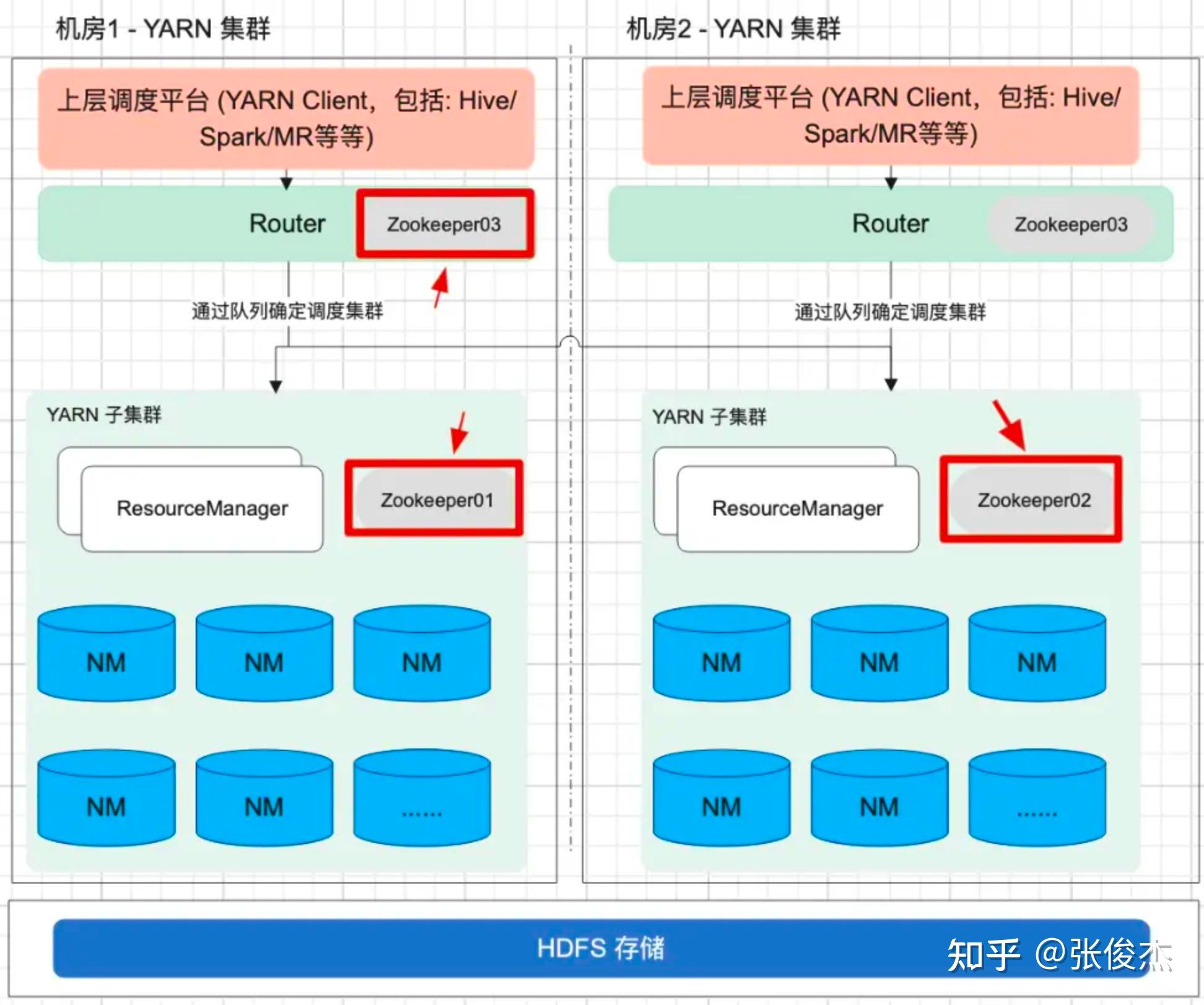 YARN Federation 整体架构图4.6 YARN Router 的高可用设计 YARN Federation 整体架构图4.6 YARN Router 的高可用设计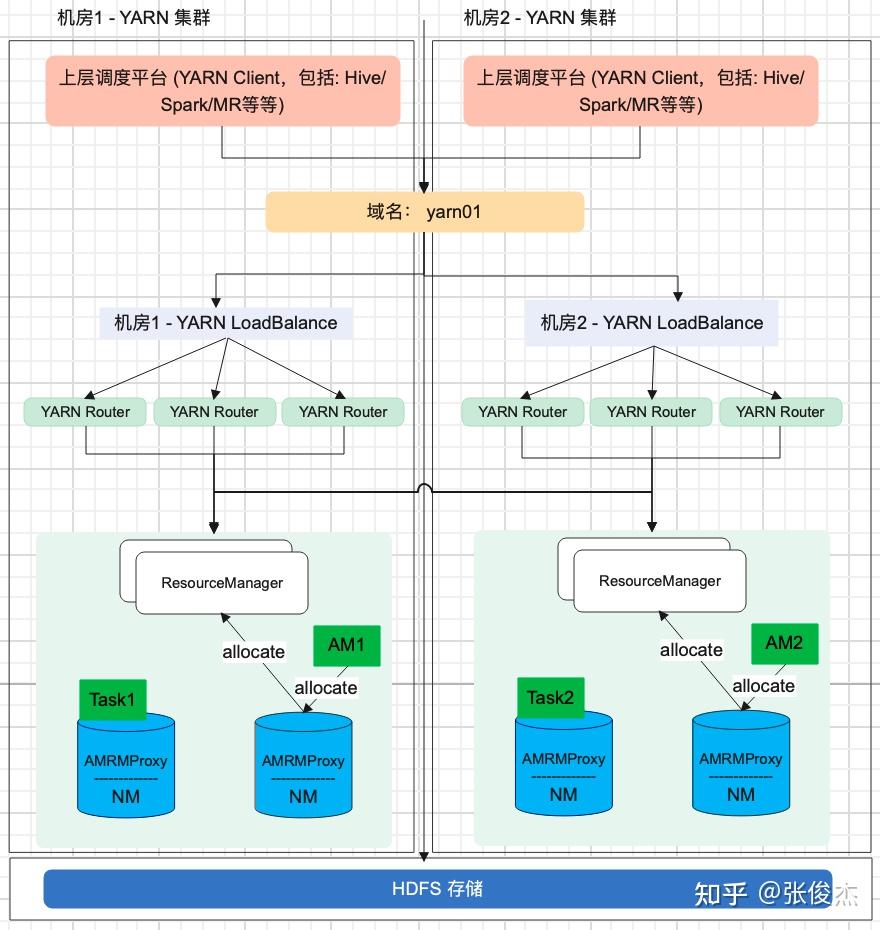 YARN Router 高可用设计 YARN Router 高可用设计因为涉及到多机房,若是业务跨机房连接 YARN Router 提交作业,存在网络延迟或者不稳定的风险。而若是每个机房都搭建一套 YARN Router,需要考虑对上层客户端进行统一配置更新。 如上图所示,知乎通过域名和负载均衡,实现不同机房使用同一域名。不同机房的域名,通过机房本地的DNS 解析,对接不同的负载均衡 LB,而 LB 对接多个 YARN Router。 这样设计的目的,是保证上层客户端配置的统一,只需配置 yarn01 即可,在不同的机房,任务会自动识别到本机房的 YARN Router 服务提交作业。同时因为 YARN Router 是无状态服务,可以搭建多个 YARN Router组件,通过 LB 的轮训调度,将作业提交到某个 YARN Router 上,保证 YARN Router 高可用。 4.7 业务作业迁移以上已经说明 YARN Federation 的跨机房搭建以及相关问题的解决,通过实现业务作业的迁移来验证架构的稳定性和便捷性。总体迁移流程图如下: 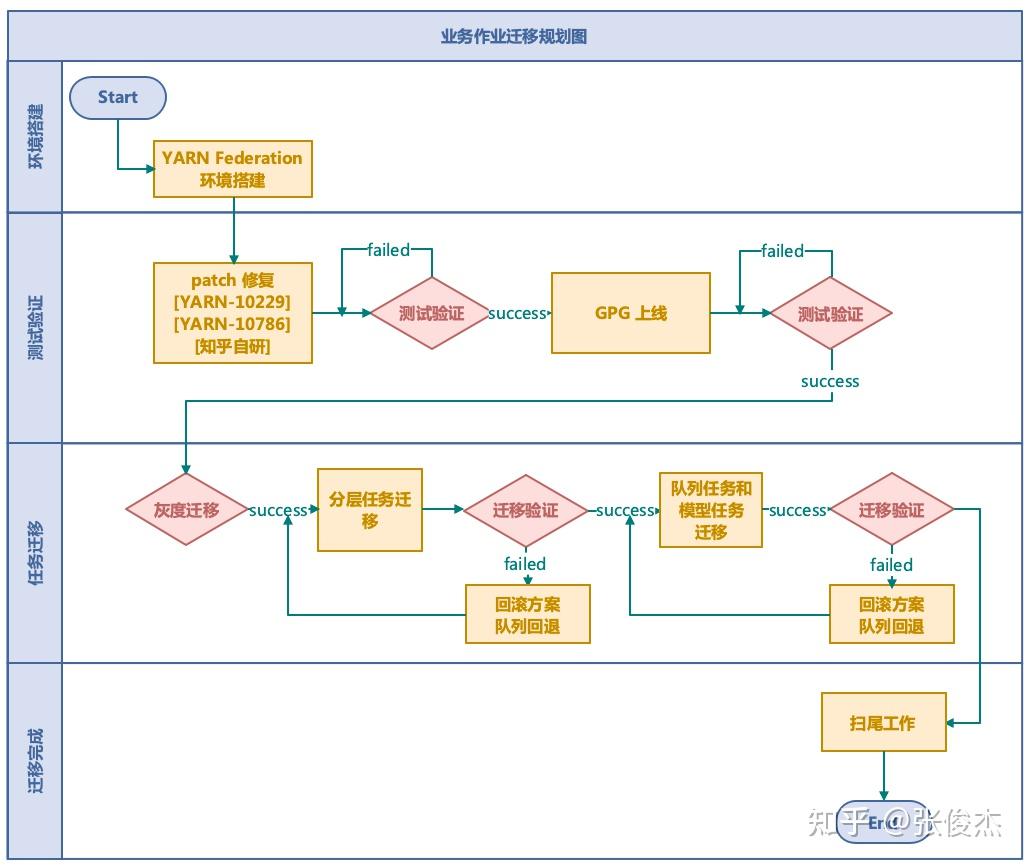 业务任务迁移规划 业务任务迁移规划业务任务迁移主要分为 4 个步骤: 环境搭建和测试验证:均在任务迁移之前进行实践操作。保证测试环境进行整轮测试没有问题。 任务迁移:该模块的目标是:实现业务任务的平滑迁移,保证做到对作业无影响。 所以先完成灰度测试,对内部低优任务进行改队列迁移操作。知乎的 YARN 集群分为低优队列和高优队列,随后迁移顺序从低优到高优进行。因为 YARN 集群涉及到上万任务,若是某些作业迁移到新集群出现问题,知乎迁移流程实现了可追溯可回滚,保证迁移集群不影响数据的正常产出。详见后续章节。 迁移完成:迁移完成后还需要很多扫尾工作,比如:验证任务是否全部迁移完成,此时通过 YARN Audit log 落表查询实现;下线 ResourceManager 保证对 GPG 删除过期 application 无影响;还有后续的 Router ZooKeeper 和 ResourceManager ZooKeeper 迁移等等。 4.7.1 任务迁移详解任务迁移的目标: 保障迁移期间专线带宽的稳定,尽可能避免出现突增的情况,影响到其他业务团队的任务运行保障迁移期间任务执行稳定,避免因为迁移而发生故障在较短时间内完成整个公司的作业迁移,并尽量降低对业务的干扰和影响4.7.2 任务迁移流量分析任务迁移过程中,跨机房迁移流量的产生主要来自于任务写流量,任务运行过程中shuffle 跨机房流量,任务读流量。 知乎避免跨机房写流量通过2种方式,其一是通过HDFS数据双写,保证两个机房均存在任务运行时所需的 HDFS 数据,双写基本可以覆盖 90% 的任务写数据量,至于剩余的 10%跨机房流量,专线带宽可以承担。其二是类似于 YARN Router实现,利用域名和负载均衡,不同机房的任务,解析本地的DNS,将数据落到本机房。 同时,避免 shuffle 跨机房流量方式,也是通过域名和负载均衡实现 shuffle 流量的本地落盘,比如 hive 运行过程中 /tmp/ 目录下的临时数据。至于 MR 运行的 shuffle 数据,通过 YARN Federation 控制策略,可以实现任务仅在某个机房运行,那么shuffle 数据也只会落盘到对应机房,不会产生跨机房流量。 至于跨专线读流量,此处需要业务配合进行客户端的改造。如下图所示:  HDFS Router 改造 HDFS Router 改造router01.defaultfs.com 为原机房1的 HDFS Router 地址,在迁移机房(从机房1迁移至机房2)之时,和 YARN Router 类似,通过域名和负载均衡,改成了 router01。如此业务作业运行,在读取数据之时,均从本地机房读取。但是若是在迁移任务过程中,读取数据的Router 地址未改,就会出现跨机房读取数据,容易导致专线带宽流程超出预期值。基于此,平台方推动上层业务方进行Router配置的修改,以及进行 Apache-Hadoop 包的源码替换。采用解析任务代码检索不规范地址的方式,每天检索一次,自动推送业务的消息通知,完成不规范任务的改造,从而保证带宽的稳定。 4.7.3 任务迁移流程任务迁移过程,主要分为以下 3 个步骤: 分层迁移:由于前期迁移对流量以及专线的不确定性,无法统一开启根目录即/user目录下的双写。需要通过上下游依赖进行数据和任务的迁移,按照数仓分层模型,从顶层的 SRC,到最终的报表完成,按照顺序实现任务迁移,保证绝大数据的任务均依赖本地数据进行计算。通过此逻辑,保证80% 的任务迁移从机房1到机房2,并确保稳定的带宽流量。队列迁移:当绝大多数的的任务以及数据迁移到机房2后,开启了/user目录的双写,按照队列迁移任务,此时的数据量基本可控。账号迁移:因为模型数据的量比较大,峰值流量能达到 Tb/s 级别,所以不能按照双写方式迁移。对于读写模型目录的任务,需要通过账号迁移,按照迁移数据->迁移任务的流程实现迁移。按照上述方式,将任务统一从机房1 迁移到机房2 中。 4.8 YARN Router 机房 ZooKeeper 迁移因为机房迁移,所以需要将 Router ZooKeeper 从机房1 迁移到机房2,在测试验证过程中发现,NodeManager 节点无法进行灰度测试,这个是生产环境无法接受的。跟踪源码发现: NodeManager 需要连接 Federation ZooKeeper 进行验证,所以知乎对 Apache-Hadoop 源码进行更改优化。 同时,ResourceManager 也存在 Router ZooKeeper 的迁移过程中,导致 YARN子集群不可用。跟踪源码发现:在 YARN子集群从 Router 模块下线之后,会改变其在 Router ZooKeeper 注册的状态,所以知乎对 Apache-Hadoop 源码进行更改优化。 还有在迁移过程中,需要通过离线的 zkcopy 方式,进行 ZooKeeper 数据的同步。 最后,在上千台集群规模的操作验证中, 完成了Router ZooKeeper 迁移和 ResourceManager ZooKeeper 迁移, 实现了对业务几乎无感知的迁移操作。 5 总结与展望最终,利用 YARN Federation 完成知乎上万离线任务的迁移工作。同时也检验了知乎 HADOOP YARN 集群在跨云多机房调度的稳定性、便捷性和可靠性。 通过升级 YARN 架构到 YARN Federation,降低了 ResourceManager 的负载问题,将复杂度降低到 HADOOP YARN 层面,利用统一配置管理提高了业务开发效率,降低了平台对 YARN 集群的运维成本。并且和调度侧的对接中,调度侧只需修改一次配置,后续 YARN 集群的改动对调度层几乎无感知,仅需修改队列即可。 最后,通过 YARN Federation 架构管理多套集群,降低了实现削峰填谷的复杂度。比如知乎正在探索的在离线混部,只需在在线环境搭建一套 YARN 集群,通过一定的规则配置,将离线资源高峰任务,迁移到在线集群运行。等到在离线混部架构在知乎环境稳定运行后,会对各位看官详细介绍此套方案,敬请期待! |
【本文地址】